
Database Design Course notes
Concepts
- Entity - Table name (e.g. user, article)
- Attribute / Field / Column
- Relation: relation between entities
- 1:1 - One to one
- 1:N - One to many
- M:N - Many to many
- Tuple / Row / Record / Entry
- Table / File: Collection of tuples or rows and attribute names
- Database design: Process of designing data tables to guarantee data integrity
- Schema: structure of the database
- Keys: Used to guarantee uniqueness. Usually IDs.
- SQL: Structured Query Language
- DDL: Data definition language. Part of SQL to define schema.
- DML: Data management language. Part of SQL to query data.
- First formal form (1NF): https://en.wikipedia.org/wiki/First_normal_form
- Atomic columns
- Value should be 1 thing. E.g. Full name should be splitted into First name and Last name
- Singular columns
- E.g. "favourite movies" would not work because you could store multiple items in the same field.
- No table column can have tables as values. Most RDBMS enforce 1NF. No SQL systems allow an attribute to have relations and subvalues.
- Atomic columns
- Parent / Child:
- In a relationship, there is always a parent and a child
- Parent: Has Primary Key (PK)
- Child: Has Foreign Key (FK)
- Intermediary table / Junction table:
- For implementing M:N relationships
- Binary relationships:
- Usually, relationships are between two entities.
- It could be between more than two entities
- Index:
- A database index is a data structure that improves the speed of data retrieval operations on a database table at the cost of additional writes and storage space to maintain the index data structure. https://en.wikipedia.org/wiki/Database_index
- Look up table
- Instead of repeating a membership like gold, silver, etc. Have a second table and reference it. Kind of Enum tables.
- user:
- | membership_id |
- membership:
- | id | membership |
Keys
- Superkey: Any number of columns that create a unique key combining the values
- There are many combinations of columns that create a unique key, so there are many superkeys.
- Candidate key: Superkey with the least number of columns
- Could have many candidate keys: email, username, ID.
- Primary key:
- Unique
- Never changing
- Never null
- Alternate key
- Unique, never changing, never null.
- Other candidate keys that are not the primary
- Surrogate key: Key that is created to guarantee uniqueness, opposed to natural keys. E.g. user_id.
- Could be autoincrement or UUID
- Surrogate are not usually given to the user. Because if you share the ID, it starts to gain meaning and become a natural key.
- Natural key: Key that occurs naturally in data. E.g. username could be a natural key.
- Surrogate key vs Natural key:
- Usually easier to use surrogate keys than natural keys
- Don't need to worry about data changing, because they will be unique
- Be consistent and always use surrogate or natural keys
- Usually easier to use surrogate keys than natural keys
- Foreign key:
- Reference to a primary key from a different table
- NOT NULL: to require and ensure there is a relationship
- Constraints
- Foreign key constraints
- ON UPDATE (if the foreign key in the parent changes)
- CASCADE: Update the foreign key to reflect the change
- RESTRICT (NO ACTION): Restrict the change in the parent table
- SET NULL: Set NULL in the foreign key column
- ON DELETE (if row with primary key referenced in foreign key is deleted)
- CASCADE: Delete the row with the foreign key
- RESTRICT (NO ACTION): Restrict the change in the parent table
- SET NULL: Set NULL in the foreign key column
- RESTRICT vs NO ACTION: In Postgres, the difference between RESTRICT and NO ACTION only arises when you define a constraint as
DEFERRABLEwith anINITIALLY DEFERREDorINITIALLY IMMEDIATEmode. https://www.postgresql.org/docs/current/sql-set-constraints.html
- ON UPDATE (if the foreign key in the parent changes)
- Simple key: One column
- Composite key: Multiple columns
- Compound key: Same as composite keys. Normally used interchangeably, but better to stick to Composite key. Compound keys usually have all of the attributes being keys to other entities (e.g. many-to-many relationships). https://dba.stackexchange.com/questions/3134/in-sql-is-it-composite-or-compound-keys
Data integrity
- Entity integrity: Ensure uniqueness in every entity. Usually solved with an ID column.
- Relational integrity / Referencial integrity: Usually managed by RDBMS to ensure relations exist and are safe.
- Foreign keys should have constraints
- Domain integrity: Data is valid and follows the expected type. Partly solved with types. Also adding validations would help.
Naming convention
- All lowercase
- E.g. user, instead of User
- Singular entity name
- E.g. user, article
- Underscores to separate entity words
- E.g. card_payment instead of CardPayment
- Name ID columns with the table name: E.g. "user" table has "user_id". This way, all the tables referencing user_id would have the same name for it, including the "user" table.
Database Relationships
- One to one
- One to many
- Many to many
One to one relationship (1:1)
Could be:
- Attribute
- If only need one data point to define the entity.
- E.g. username: text
- Foreign key to another table
- If you have more than one attribute for the same entity
- E.g. Card number, card name, card issue date, etc.
- Add foreign key on parent table
- | user | card_id |
- | card |
- If you have more than one attribute for the same entity
One to many relationship (1:N)
- Add foreign key to child table
- | user |
- | card | user_id |
Many to many relationship (M:N)
- Create a Intermediary / Junction table:
- | user |
- | user_id | card_id |
- | card |
Entity relationship modeling
Standard for drawing schemas
- ER Model: Entity-relationship model
- ERD: entity relationship diagram
- EER Model: Enhanced entity-relationship model
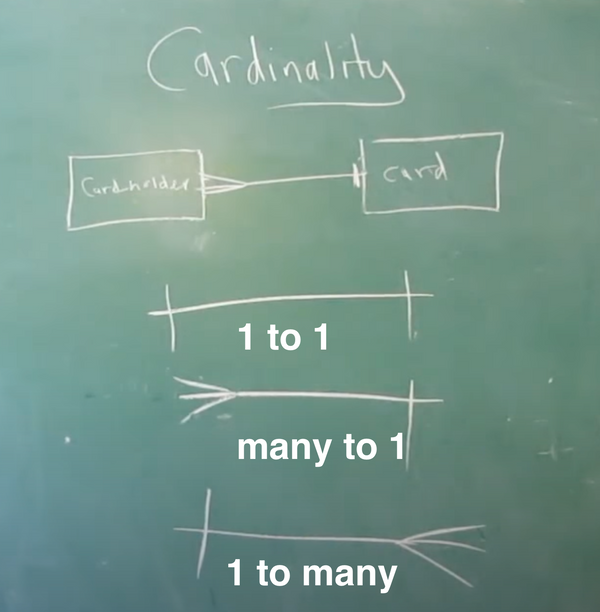
- Cardinality:
- Multiple lines represent Many
- One vertical line represents 1
- Modality:
- A 0 represents that the foreign key can be null, so there could be rows that don't have a parent.
- Read as 0 or 1.
- A line represents 1. Read as 1 or 1 when two vertical lines are displayed. It means that the foreign key has a NOT NULL constraint.
- A 0 represents that the foreign key can be null, so there could be rows that don't have a parent.

Normalization
- 1NF: First normal form
- Making everything atomic
- A relation is in first normal form if and only if no attribute domain have relations as elements.
- Basically, if a field has multiple values, that should be split into two tables.
- | user_id |
- | email_id | email | user_id (fk) | (this allows for multiple emails)
- 2NF: Second normal form
- Removing partial dependencies
- A relation is in 2NF if it is in 1NF.
- There are no partial dependencies for the relationship.
- E.g.
- user: | user_id |
- book_author: | book_id | user_id | book_summary (wrong because it depends on the book_id) |
- book: | book_id | title |
- 3NF: Third normal form
- Removing transitive dependencies
- E.g. poor design:
- | review_id | stars | stars_meaning |
- Star meaning changes with stars, so depends on something that is not a key
- E.g. better design:
- | review_id | star_id |
- | star_id | stars | stars_meaning |
Indexes
- Clustered
- Reorganizes the data
- Can only have one
- Non clustered
- Points to the data
- E.g. end of the book index
- Can have multiple
- Composite
- Index on multiple columns
Pros:
- Faster queries
Cons:
- Storage and memory
- Need to update the index when changes on the data happen. Writes are slower.
Joins
- https://en.wikipedia.org/wiki/Join_(SQL)
- INNER JOIN (default JOIN)
- Default join between two tables
- Only returns the rows that match the condition in both tables
- Outer joins
- Include all columns that don't match one in the joined table, including null values.
- When the joined column is a foreign key and NOT NULL, outer joins would return the same than inner joins.
- Types:
- Left outer join (default): Include all non-matching rows in the left table
- Right outer join: Include all non-matching rows in the right table
- Full outer join: Include non-matching rows from all tables
- Self join:
- Join a table with itself
- For example:
- | user_id | name | referred_by |
- Self join on the referred_by to find the user and the referral
SELECT u1.name, u2.name AS "referred_by"
FROM user AS u1
INNER JOIN user AS u2
ON u1.referred_by = u2.user_id